See Techempower. This repository contains homemade java benchmarks using spring-mvc, spring-webflux and netty-http/netty-tcp servers based on reactor-netty. gin and gnet are also included. wrk is used as client. gobench is also considered but it is not so good as wrk.
2 VM Clients are not able to fully utilize the server capability. The initial attempts were benchmarking only first 4 cases. And the go-gnet results made me wonder, it can give much more throughput. After reading the source of it, I found go-gnet case is actually a TCP server with very very little of HTTP implementation to fulfill the benchmark, which is unfair for other cases. Therefore, I added case 5/6 in java to align with it.
Environment 2
Server: 24C32G physical machine
Client:
4C8G vm * 2
8C16G vm * 1
24C32G physical machine * 1
Server
Server Throughput
Server CPU
spring-mvc
~120k /s
~1560%
spring-webflux
~180k /s
~2380%
go-gin
~380k /s
~2350%
go-gnet
560k ~ 580k /s
~1160%
netty-http
560k ~ 580k /s
~2350%
netty-tcp
560k ~ 580k /s
~1460%
Still room to give more throughput in go-gnet and netty-tcp cases. Not having so many idle systems for benchmarking now. The throughput should have a linear increment when more CPU is utilized, in both cases.
As a developer, spring-mvc or go-gin can still be the first choice, as they are easier to get started.
Recently played with the Spring/SpringBoot/SpringCloud stack with a toy project: https://github.com/gonwan/spring-cloud-demo. Just paste README.md here, and any pull request is welcome:
Switch from Postgres to MySQL, and from Kafka to RabbitMQ.
Easier local debugging by switching off service discovery and remote config file lookup.
Kubernetes support.
Swagger Integration.
Spring Boot Admin Integration.
The project includes:
[eureka-server]: Service for service discovery. Registered services are shown on its web frontend, running at 8761 port.
[config-server]: Service for config file management. Config files can be accessed via: http://${config-server}:8888/${appname}/${profile}. Where ${appname} is spring.application.name and ${profile} is something like dev, prd or default.
[zipkin-server]: Service to aggregate distributed tracing data, working with spring-cloud-sleuth. It runs at 9411 port. All cross service requests, message bus delivery are traced by default.
[zuul-server]: Gateway service to route requests, running at 5555 port.
[authentication-service]: OAuth2 enabled authentication service running at 8901. Redis is used for token cache. JWT support is also included. Spring Cloud Security 2.0 saves a lot when building this kind of services.
[organization-service]: Application service holding organization information, running at 8085. It also acts as an OAuth2 client to authentication-service for authorization.
[license-service]: Application service holding license information, running at 8080. It also acts as an OAuth2 client to authentication-service for authorization.
[config]: Config files hosted to be accessed by config-server.
[docker]: Docker compose support.
[kubernetes]: Kubernetes support.
NOTE: The new OAuth2 support in Spring is actively being developed. All functions are merging into core Spring Security 5. As a result, current implementation is suppose to change. See:
Every response contains a correlation ID to help diagnose possible failures among service call. Run with curl -v to get it:
1
2
3
4
# curl -v ...
...
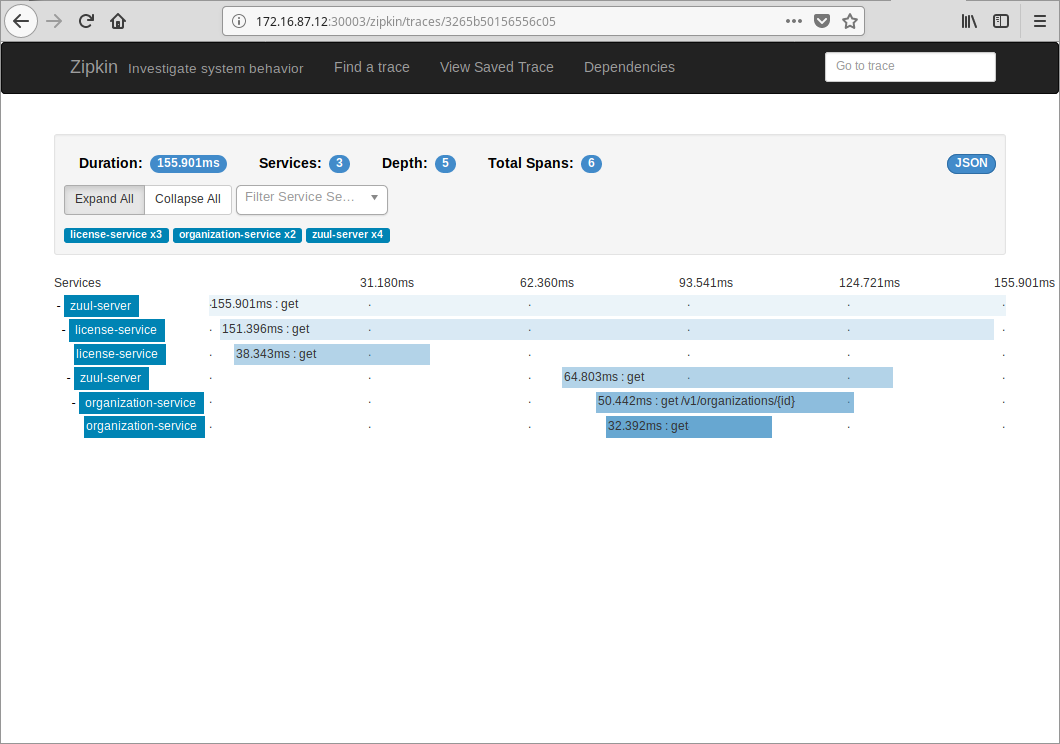
<sc-correlation-id:3265b50156556c05
...
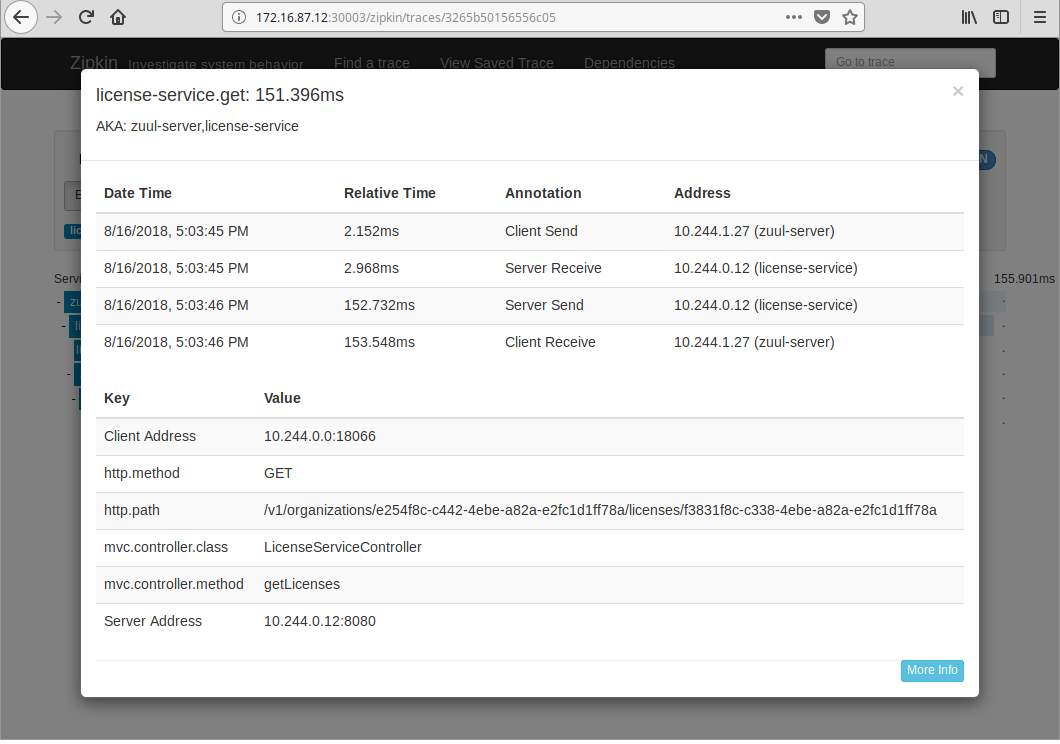
Search it in Zipkin to get all trace info, including latencies if you are interested in.
The license service caches organization info in Redis, prefixed with organizations:. So you may want to clear them to get a complete tracing of cross service invoke.
All OAuth2 tokens are cached in Redis, prefixed with oauth2:. There is also JWT token support. Comment/Uncomment @Configuration in AuthorizationServerConfiguration and JwtAuthorizationServerConfiguration classes to switch it on/off.
Swagger Integration
The organization service and license service have Swagger integration. Access via /swagger-ui.html.
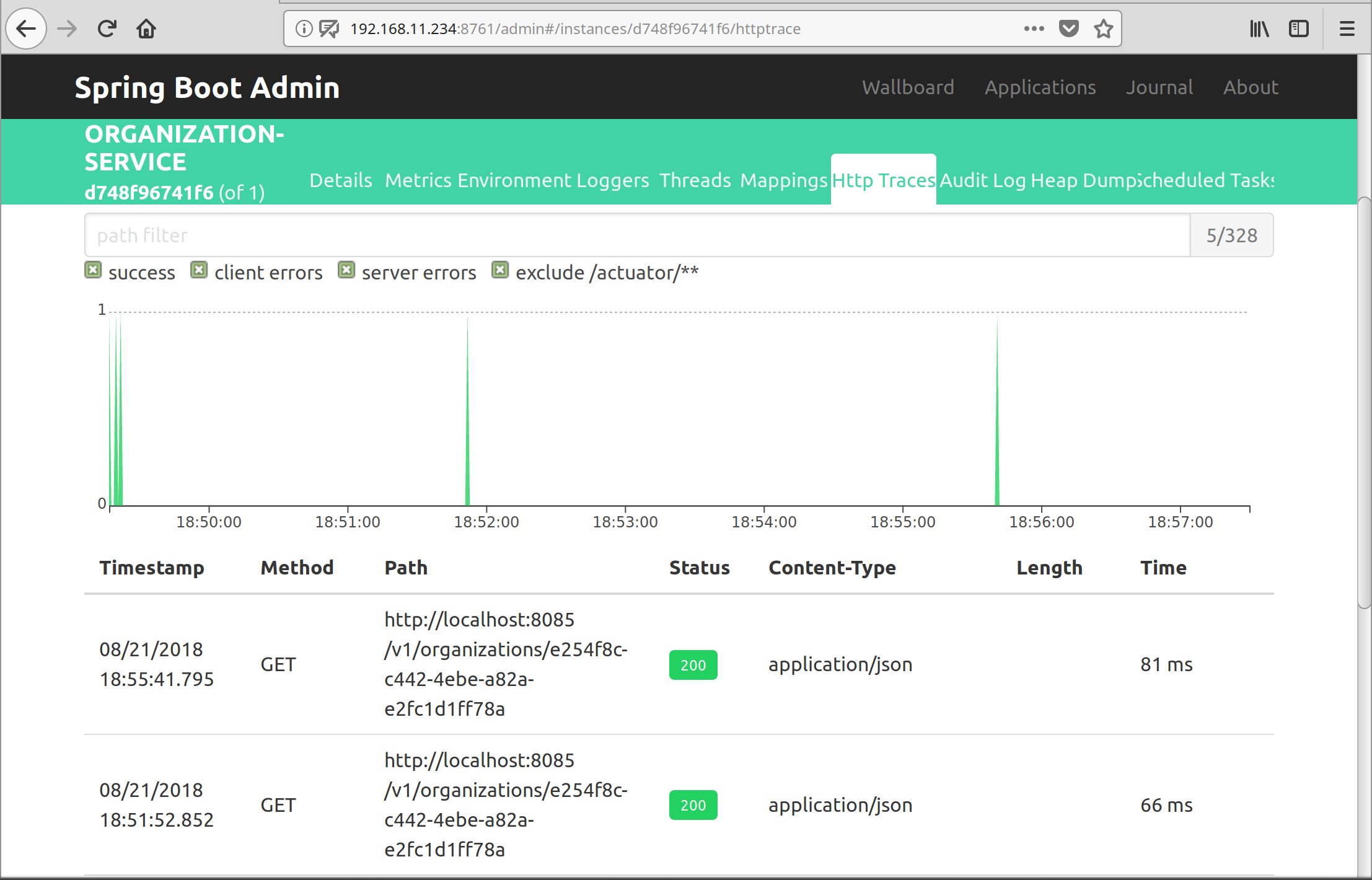
Spring Boot Admin Integration
Spring Boot Admin is integrated into the eureka server. Access via: http://${eureka-server}:8761/admin.
Adopting to using Spring Data JPA these day, there is a post saying: IDENTITY generator disables JDBC batch inserts. To figure out the impact, create a table with 10 data fields and an auto-increment id for testing. I am using MySQL 5.7.20 / MariaDB 10.3.3 / Spring Data JPA 1.11.8 / Hibernate 5.0.12.
MySQL
1
2
3
4
5
6
7
8
9
10
11
12
13
14
CREATETABLE`t_user`(
`id`int(11)NOT NULLAUTO_INCREMENT,
`field1`varchar(255)DEFAULTNULL,
`field2`varchar(255)DEFAULTNULL,
`field3`varchar(255)DEFAULTNULL,
`field4`varchar(255)DEFAULTNULL,
`field5`varchar(255)DEFAULTNULL,
`field6`varchar(255)DEFAULTNULL,
`field7`varchar(255)DEFAULTNULL,
`field8`varchar(255)DEFAULTNULL,
`field9`varchar(255)DEFAULTNULL,
`field10`varchar(255)DEFAULTNULL,
PRIMARY KEY(`id`)
)ENGINE=InnoDBDEFAULTCHARSET=utf8;
And generate the persistence entity, add @GeneratedValue annotation:
As mentioned, Hibernate/JPA disables batch insert when using IDENTITY. Look into org.hibernate.event.internal.AbstractSaveEventListener#saveWithGeneratedId() for details. To make it clear, it DOES run faster when insert multiple entities in one transaction than in separated transactions. It saves transaction overhead, not round-trip overhead.
The generated key is eventually retrieved from java.sql.Statement#getGeneratedKeys(). And datasource-proxy is used to display the underlining SQL generated.
2. TABLE
Now switch to GenerationType.TABLE. Just uncomment the corresponding @GeneratedValue and @TableGenerator annotation. Result looks like:
I began to think that was the whole story for batch, and the datasource-proxy interceptor also traced down the batch SQL. But after I looked into dumped TCP packages using wireshark, I found the final SQL was still not in batch format. Say, they were in:
The latter one saves client/server round-trips and is recommended by MySQL. After adding rewriteBatchedStatements=true to my connection string, MySQL generated batch statements and result was much improved:
Last switch to GenerationType.SEQUENCE. Sequence is a new feature added in MariaDB 10.3 series. Create a sequence in MariaDB with:
MySQL
1
CREATESEQUENCE`s_user`STARTWITH1INCREMENTBY100;
Generally, the increment should match the one specified in @SequenceGenerator, at least >= allocationSize. See org.hibernate.id.enhanced.PooledOptimizer#generate().
Hibernate apparently does not support the new feature, I dealt with it by adding a new dialect:
Java
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
packagecom.gonwan.spring;
importorg.hibernate.dialect.MySQL5Dialect;
/*
* Copied from org.hibernate.dialect.PostgreSQL81Dialect.
supportsSequences() adds the sequence support. supportsPooledSequences() adds some pool-like optimization both supported by MariaDB and Hibernate. Otherwise, Hibernate uses tables to mimic sequences. Refer to org.hibernate.id.enhanced.SequenceStyleGenerator#buildDatabaseStructure(). Result with and without batch:
Dramatically improved when compared to the table generator. A sequence generator uses cache in memory(default 1000), and is optimized to eliminate lock when generating IDs.
4. Summary
1 thread
2 threads
4 threads
8 threads
16 threads
32 threads
IDENTITY
823
609
1188
2329
4577
9579
TABLE
830
854
1775
3479
6542
13768
TABLE with batch
433
409
708
1566
2926
6388
SEQUENCE
723
615
1147
2195
4687
9312
SEQUENCE with batch
298
155
186
356
695
1545
From the summary table, IDENTITY is simplest. TABLE is a compromise to support batch insert. And SEQUENCE yields the best performance. Find the entire project in Github.
The article is inspired by the posts here and here.
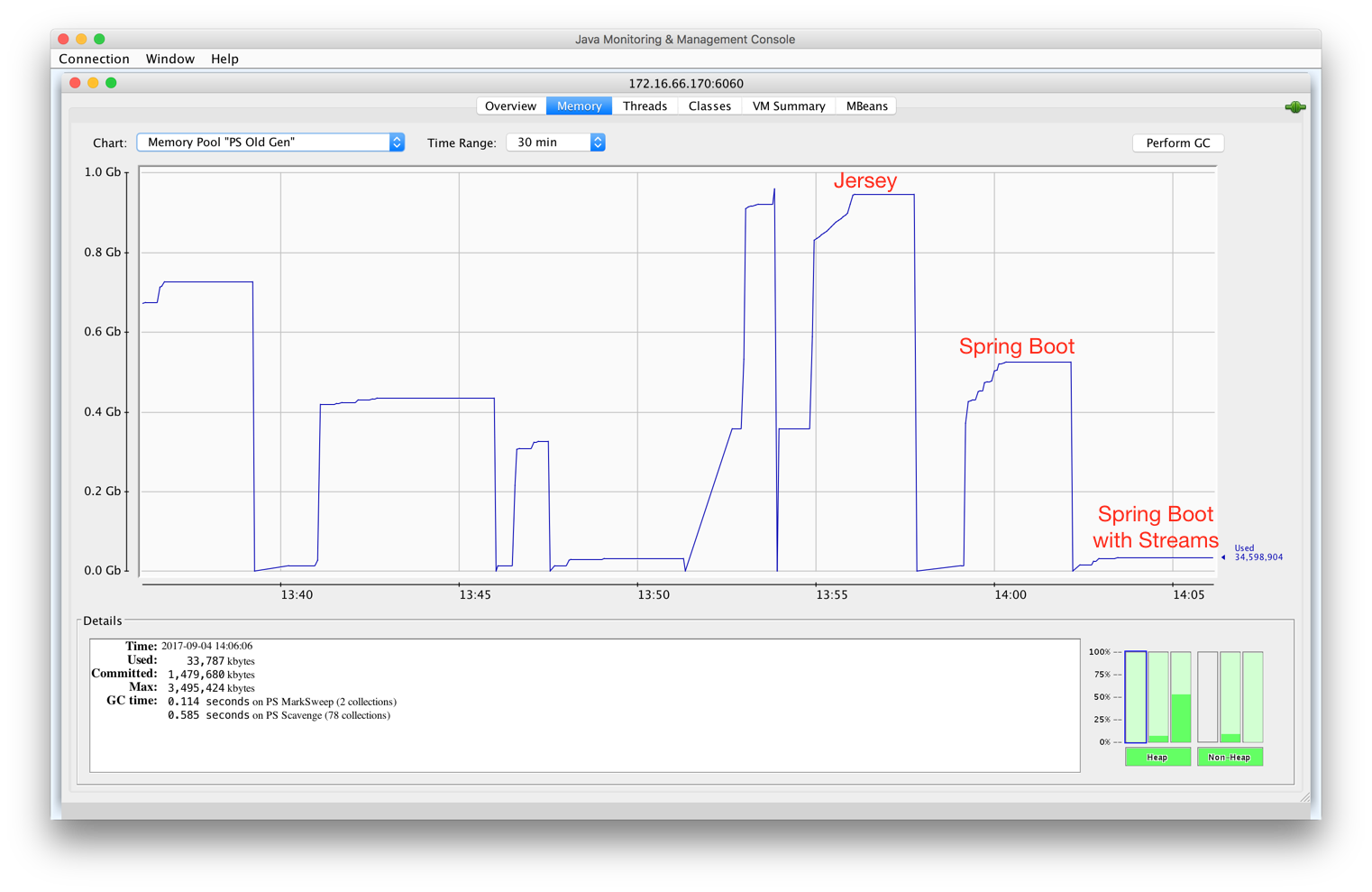
There is a RESTful service as the infrastructure for data access in our team. It is based on Jersey/JAX-RS and runs fast. However, it consumes large memory when constructing large data set as response. Since it builds the entire response in memory before sending it.
As suggested in the above posts. Streaming is the solution. They integrated Hibernate or Spring Data for easy adoption. But I need a general purpose RESTful service, say, I do not know the schema of a table. So I decided to implement it myself using raw JDBC interface.
My class is so-called MysqlStreamTemplate:
It does not extend JdbcTemplate, since there is only one interface for streaming, not one series. I’m not writing a general purpose library.
It is MySQL only, I have no time to verify with other relation databases.
It does accept a DataSource as the parameter of the its constructor.
Staff like Hibernate session is not concerned, since it maintains Statement & Connection by itself.
Staff like @Transcational is not concerned, since we do not care about transactions. Actually, MySQL gives HOLD_CURSORS_OVER_COMMIT in StatementImpl#getResultSetHoldability() in its JDBC driver, saying that our ResultSet survives after commit.
So, here is my class. NOTE: closing our Statement & Connection requires explicit invoke of Stream#close():